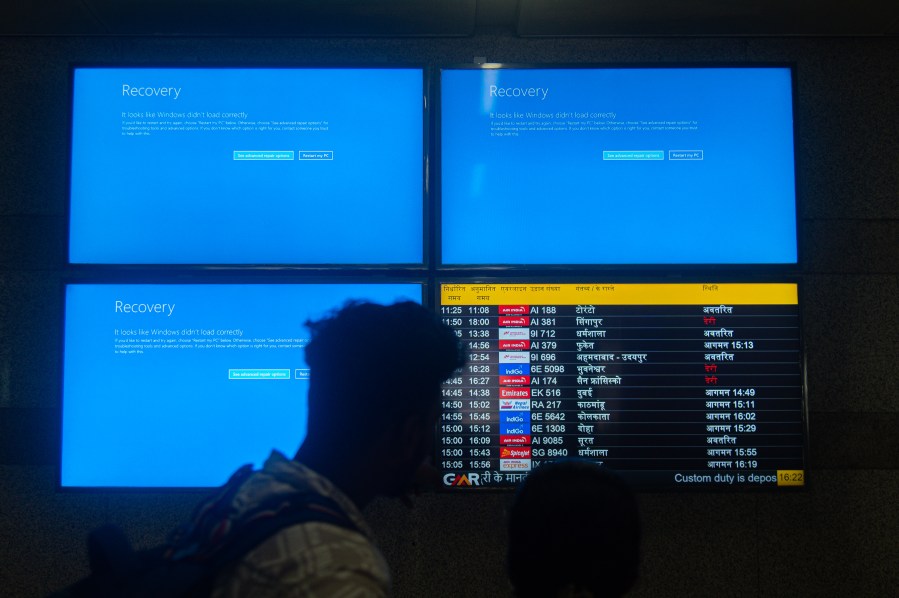
Businesses, governments and airlines across the world experienced hours-long disruptions on Friday after a widespread technology outage caused by a faulty software update.
CrowdStrike, a cybersecurity firm that provides software to thousands of companies around the world, says the problem occurred when it deployed a faulty update to computers running Microsoft Windows.
The outage was not caused by a security incident or cyberattack, CrowdStrike said.
The global outage had local impacts, as several major airlines canceled flights out of LAX on Friday and shipments at local ports were briefly interrupted.
Delays and cancellations continued into Saturday; according to flight tracking software FlightAware, 279 flights were delayed and a further 90 were canceled at LAX as of 1 p.m.
{kind=link}
Consumer technology expert and former Microsoft executive Marbue Brown joined the KTLA 5 Weekend Morning News on Saturday to discuss the global IT crash, including how it happened, what the impacts are and whether something like this could happen again.
“This happened because you have so many companies that are using the same cybersecurity provider, and it’s not just the number of businesses, but the types of businesses,” Brown said. “You have these major businesses that touch everybody’s life and that’s why the impact of this was felt so widely.”
One “super important” thing to note, Brown told KTLA 5’s Lauren Lyster and John Fenoglio, is that the glitch didn’t just affect individual computers, it also affected the servers that host the software that the individual computers and businesses use.
“Because those servers were affected, once they went down, a lot of other things went down,” Brown said. “If all of the businesses are using the same cybersecurity firm as the basis for protecting their software and they roll out the same update at the same time, then [there’s going to be] a problem since all of these businesses are experiencing the same thing simultaneously.”
When it comes to why companies that operate on Microsoft went dark but Microsoft applications such as Microsoft Teams and Microsoft Outlook did not, Brown says it’s the specific information that is stored on servers that was affected; Teams and Outlook did not have any information stored on those servers, Brown said.
“When you think about what’s on those servers, if Teams and Outlook were on the servers, that’s what would [have been] affected,” Brown stated. “But, if critical systems like order taking systems, point-of-sale systems, airline scheduling systems [and] systems that [help to run] hospitals are affected, that [would be] why we had the type of problem that we had.”
According to Brown, the telecommunications business has gradually shifted from the industry standard “five nines reliability” procedure — which ensures systems are meant to be fully operational 99.999% of the time, or the entire year minus about six minutes — due to it being cost-prohibitive or impractical.

However, the situation like the one that arose on Friday shows that redundancies like “five nines reliability” should be put in prior to updates, Brown said.
“Something obviously went awry here because normally, these updates are heavily tested before they go out,” he said. “But I think that the whole notion of going back to the ‘five nines’ and [building] the redundancies will keep us from having these types of situations.”
When asked about the possibility of another catastrophic IT outage, Brown says that it “is still possible” and has already happened this year, as seen in February when AT&T had an outage due to a faulty software update.
The possibility only increases when redundancies are not properly instituted, he added.
“It’s clear that the type of redundancies that we need to have in place and the type of rollbacks that we need to have in place are not where they once used to be,” he said. “One of the reasons it’s taking so long for everything [that went down during the CrowdStrike outage] to come back is because to roll back from this, a lot of systems have to be rebooted manually…they have to be booted up in safe mode, [have the software file] manually removed and booted up again.”
For more from Marbue Brown, visit his Customer Obsession Advantage website.